Everything you need to start, scale and manage your business.
Sell any type of digital download such as ebooks, software, design assets, templates, video, music and more. If you can save it, you can sell it.
Learn moreCreate online courses with rich features such as videos, digital files, quizzes and assignments. Publish drip courses and provide completion certificates.
Learn moreSell your expertise through 1:1 coaching sessions. Easily set up online meetings with clients using integrations with Zoom, Calendly and more.
Learn moreAllow your customers to pay you on a recurring basis to access your digital downloads or membership group. Manage your members easily.
Learn moreSell and manage inventory for any physical products. Manage your store, fulfill orders, run promotions and more.
Learn more

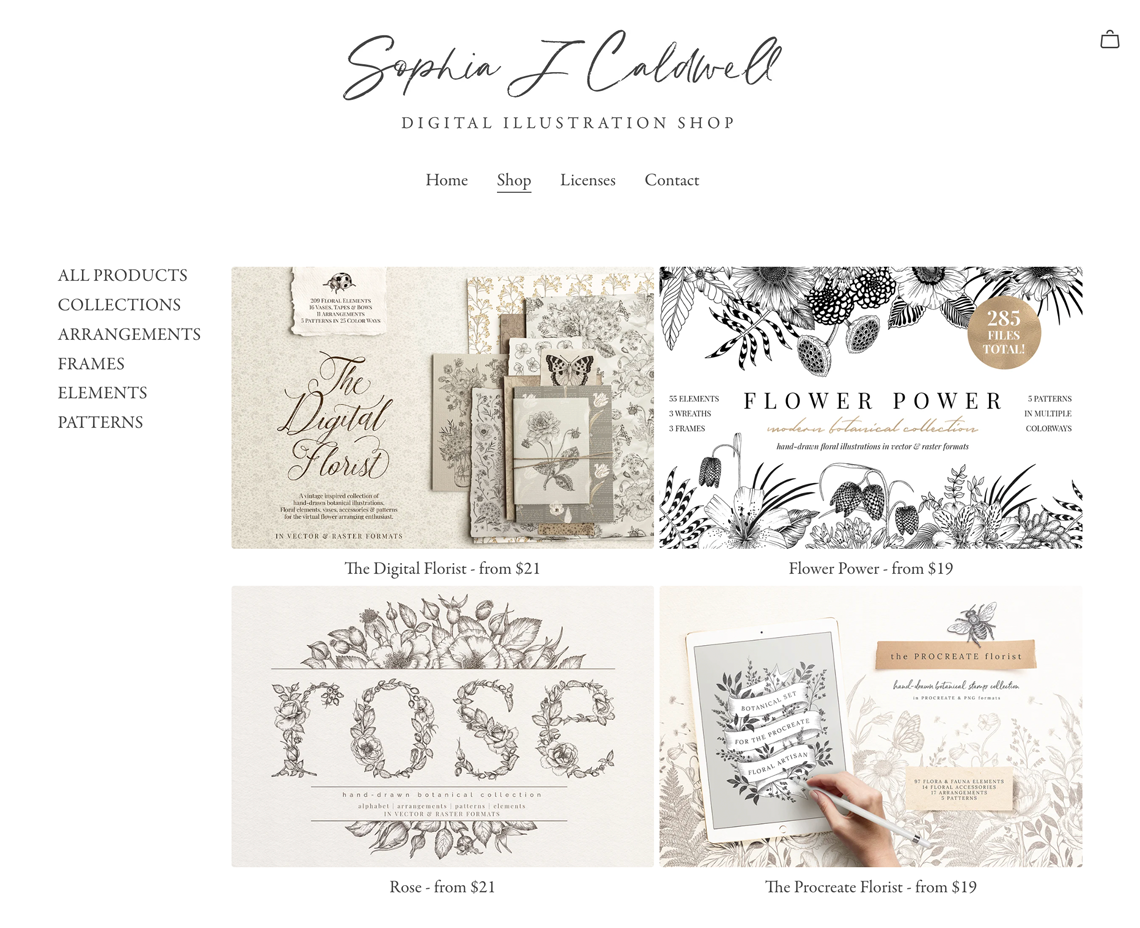
Thoughtful features that help your brand shine.
Our fully customizable store builder helps you create the website of your dreams. No coding required.
Establish your brand further by connecting your own domain to Payhip for free. You can connect your main domain or a subdomain.
Bring Payhip's robust features and high-converting checkout experience to any existing website with our simple embed feature.
Want to learn more about these features? Explore
We help creators grow their business and turn their passion into profit.
Payhip is fantastic. The interface is simple, the integration easy and the customer service has been top notch. I'm really glad I chose Payhip and will continue to do so in the future.

I absolutely love Payhip, it's such a user-friendly platform that literally anyone can use. Having launched my first ever eBook with Payhip, everything has gone by a breeze, I couldn't be happier with how easy it is.

We needed a company that handled VAT of the eBooks we sell. After a little research, we found Payhip to be the best fit. We're now using Payhip. We love the way they handle VAT and are easy to work with!

Check out these amazing sellers on Payhip.
We're here for you, every step of the way.
Contact support 24/7, whether you're troubleshooting issues or looking for advice.
Contact supportThe help center has articles on all parts of Payhip and may shed some light on your issue.
View help center
Join over 130,000 ambitious sellers who power their business with Payhip




















